Note: To report bugs with the package, please file an issue on the Github page.
If you use this package, please cite the following:
Kubinec, Robert. “Generalized Ideal Point Models for Robust Measurement with Dirty Data in the Social Sciences.”
This package implements to kinds of time-varying ideal point models. Because these time-varying models are independent of the specific outcome used, time-varying ideal point models can be fit with any outcome/response supported by the package, including binary, ordinal, counts, continuous and positive-continuous data, in addition to the latent space model for binary data. This vignette demonstrates the use of the two time-varying ideal point models and how to decide between them with example data drawn from Delaware’s state legislature.
The process to create a time-varying ideal point model is no different than that for creating a static model, except that a column should exist in the data with dates, preferably in date or date-time format. If you have a character vector of dates that you need to convert to R’s date format, check out the excellent lubridate package.
There are four time-varying models included in idealstan package, each of which makes different assumptions about how ideal points change over time. It is important to note that none of these models is superior to the other. Ideal points do not have any natural time process as they are a latent, unobserved construct, so the question is more about which time process is most relevant to the social or physical process being studied. The models can be differentiated by whether they permit general description of time series versus inference on specific aspects, and also in terms of complexity.
The first kind of model included in idealstan is known as a random-walk process (also known as non-stationary time-series, Brownian motion and I(1)). This simple model of time implies that the location of an ideal point in the current time point is equal to the position of the ideal point in the prior time point plus some random noise. A helpful analogy is to imagine a frog hopping around a room. It could head in virtually any direction.
The advantage of the random-walk model is that it allows ideal points to move in any direction. The downside is that it can assume too much change in the ideal point process. It also does not provide a great deal of information about the time series other than the variance parameter of the time series that indicate the average rate of change over time (i.e., how bouncy the time series is). Furthermore, random-walk models change significantly when other covariates are included in the model, as an additional covariate that has a constant effect over time will push the time-series in a single direction, making it less than ideal for testing the effect of time-varying covariates.
Despite these limitations, this model is still useful, especially in two situations. First, when little is known about the time process/social situation, this model makes the most minimal assumptions about how ideal points change. Second, when the time series is of a relatively long time period, then the time series is likely to have some kind of random-walk nature, especially if there is no natural limit. For example, when looking at legislature voting data, ideal points may follow a random-walk pattern when looking at a legislator’s entire career over decades. In general, a random walk provides a good descriptive inference of where the ideal points are moving; it just won’t tell you a lot about why.
The second model included in idealstan is a stationary time series model (also called an AR(1) or first-order autoregressive time series). A stationary time-series is so called because it must return over time to a long-term average or mean. Change over time is conceived of as shocks that push the time series away from its long-term average. The AR(1) model includes additional parameters that measure how fast a time-series will return to its long-term average. A good empirical example for this model is economic growth over time. There are periods when “growth shocks” occur, such as recessions and boom times. Overall, though, economic growth for a specific country will tend towards some long-term average rate of growth. Economic growth can’t simply move off in any direction, especially in an upward direction, as that would over-heat the economy and result in massive inflation.
The third model is known as a Gaussian process. Fully explaining how Gaussian processes work is beyond the scope of this vignette, but I refer readers to this case study as a very helpful introduction. A Gaussian process is similar to a random walk in that it can in principle move in any direction. Unlike a random walk, the prior position of the time series doesn’t necessarily constrain the position of the time series in the present position. Rather, a Gaussian process is a generalized smoother: it will find a smooth path between the points, but can take any shape in principle.
One major advantage of the Gaussian process is that it is a so-called continuous time series model. In practice this means that the time series does not have to be sequential. For example, if legislators only vote at irregular intervals, and the fact that some bills are separated than more time than others is important, then a Gaussian process will take into account the actual length of time between each vote. Random walks and stationary models, on the other hand, consider each time point to be sequential to the previous time point, effectively ignoring any big gaps.
The main disadvantage of the Gaussian process is that the power and flexbility require a lot more data. It is not a useful model unless you have considerable numbers of bills/items. The model can handle additional time-varying covariates although their meaning is not as precise as the stationary model.
The stationary model, by contrast, assumes that ideal points have a single long-term average. The ideal points may receive “shocks” that force them away from the long-term mean, but they will inevitably return. While this is a more specific set of assumptions than the random walk or Gaussian process, stationary models have the significant advantage of allowing us to fit covariates that have a more meaningful interpretation: the estimates of covariates represent shocks to the ideal points away from their long-term average.
A simpler kind of time series model is also available in idealstan known as splines. Splines are combinations of polynomial functions; the more combinations, the more flexible splines become. idealstan includes splines primarily because it is easy to estimate relatively simple time series functions that are useful when there is only a limited amount of data per time point and when the latent trait is unlikely change very quickly. In these cases, a spline can help estimate a latent trait that varies over time but only within certain bounds defined by the complexity of the polynomial function.
To show what these models look like, we will fit each model to the delaware data in turn. We use the use_vb option to produce variational estimates of the true posterior; these approximations are much faster to fit than the full model but usually have some distortions. For finished analysis we would want to use the full sampler (use_vb=FALSE), unless we have so much data that processing time for the full model is infeasible.
The models will be fit with parallel processing over the persons in the model (i.e. more ncores than nchains specified in id_estimate). Parallel processing is only possible for persons as time series model introduce dependence between time points. As such do not change the map_over_id option for dynamic models or you will get incorrect results.
Random-Walk Model
To fit the random walk model, we first create data in which we pass the name of the column of dates for each bill/item to the time_id option of id_make. One important thing to note about this model is that we code missing values as 'Absent', but we leave NA values in the outcome. These NA values will be dropped before running the model. They represent periods of time when legislators were not in office, and hence it is reasonable to exclude these periods of time from analysis.
# Absent to missingdelaware$outcome[delaware$outcome=="Absent"] <-NA# adjust data to 0/1delaware$outcome <-as.numeric(delaware$outcome=="Yes")delaware_data <-id_make(delaware,outcome_disc ='outcome',person_id ='person_id',item_id ='item_id',group_id='group_id',time_id='time_id')
We then pass this object to the id_estimate function and specify 'random_walk' in the vary_ideal_pts option. We also use model_type=2 to select a binary model (yes/no votes) that adjust for the missing data (legislator absences). We pass the names of two rollcall votes to restrict their item discrimination parameters for identification (i.e. we constrain one vote with all Republicans voting for to be positive and one vote with all Democrats voting for to be negative). To do so, we need to set the const_type argument to "items" and pass the name of bills to the restrict_ind_high and restrict_ind_low options. Using bills (or whatever indicators are in the data) that have a clear split in the votes between parties will help achieve identification, as well as using bills that are far apart in time.
One problem with time-varying models is that they introduce additional identification issues with the ideal point scores. Theoretically, if over-time variance is high enough, ideal point scores can oscillate from positive to negative. In these cases, you can add additional items to constrain via the restrict_ind_high and restrict_ind_low options or use a simpler time-series model like a spline with few degrees.
# parallel processing over persons/legislators specified with# ncores = 16 and nchains = 2# this will equal 8 cores per chain.# of course your machine must have 16 cores for # that number to be usefuldel_est <-id_estimate(delaware_data,model_type =1,fixtype='prefix',const_type="items",nchains =2,use_vb = T,ncores =8,vary_ideal_pts='random_walk',restrict_ind_high =305,restrict_ind_low=276,seed=84520,id_refresh=0)
[1] "Running pathfinder to find starting values"
Finished in 7.6 seconds.
[1] "Estimating model with Pathfinder for inference (approximation of true posterior)."
Pareto k value (33) is greater than 0.7. Importance resampling was not able to improve the approximation, which may indicate that the approximation itself is poor.
Finished in 7.7 seconds.
It is important to note that the warnings about importance resampling and the approximation do matter and a run with the Hamiltonian Markov Chain sampler should be used before final inferences by setting use_vb=TRUE. The approximation is only useful for exploratory model development.
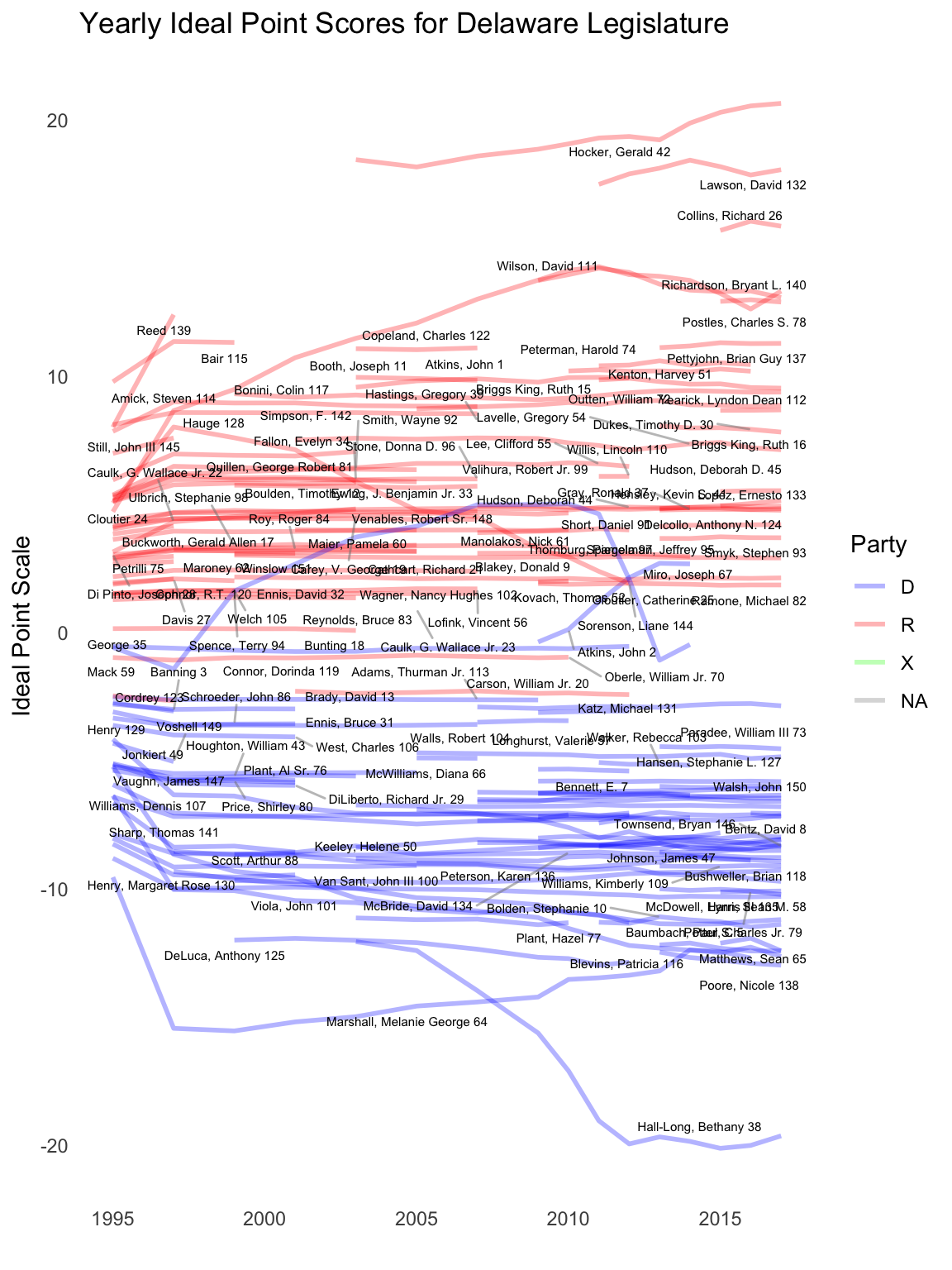
Given the fitted model, we can now plot the ideal points. We will turn off the option for showing the uncertainty interval as there are a lot of lines, one for each legislator:
id_plot_legis_dyn(del_est,use_ci = T) +scale_color_manual(values=c(R='red',D='blue',X='green'),name="Party") +ggtitle("Yearly Ideal Point Scores for Delaware Legislature")
This plot does now show very much that is particularly interesting. Most of the ideal points are not changing over time, although it is important to note that polarization is increasing over time–both within parties and between parties as some legislators move to the extremes.
We can also look at the variance of the ideal points to see which of the legislators had the highest variance in their ideal points:
id_plot_legis_var(del_est) +ggtitle('Variances of Time-Varying Ideal Points in Delaware State Legislature',subtitle='Higher Variances Indicate Less Stable Ideal Points') +scale_color_manual(values=c(R='red',D='blue',X='green'))
We can access the actual estimates of the variances by passing the return_data=TRUE option to the plot function:
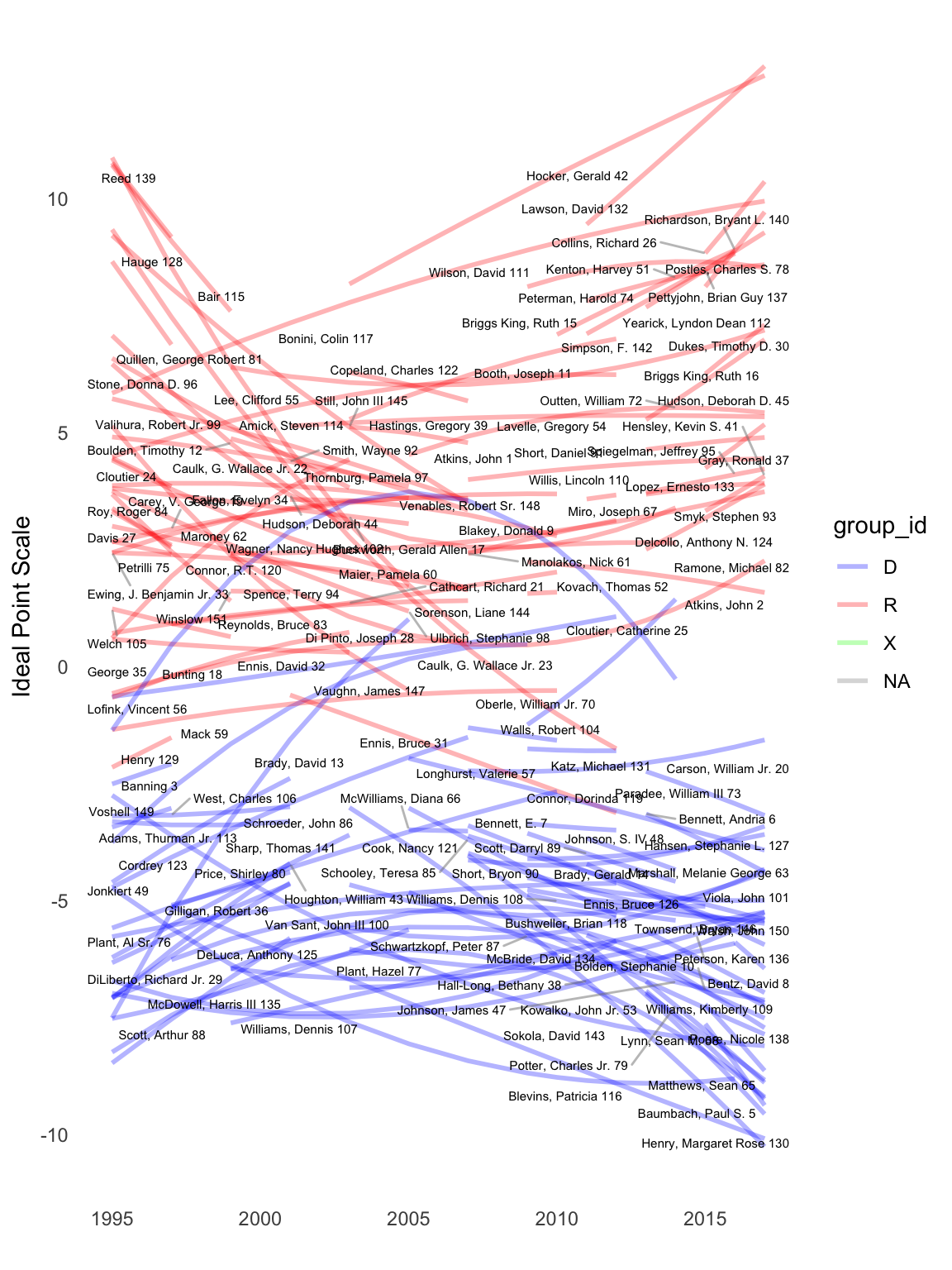
We now fit a form of splines for the legislator trajectories by passing 'splines' to vary_ideal_pts. This model has two main control parameters - spline_degree and spline_knots. The first is equal to the number of polynomial coefficients or “bends” in the time series – for a value of 2 the model is quadratic, with 3 it is a sigmoid (three bends), with 4 there is an additional possible bend in the time series, and so on. We will fit a restrictive time-varying model with 0 knots (equivalent to a single polynomial function) and only 2 degrees for the polynomial function:
[1] "Running pathfinder to find starting values"
Finished in 5.7 seconds.
[1] "Estimating model with Pathfinder for inference (approximation of true posterior)."
Pareto k value (36) is greater than 0.7. Importance resampling was not able to improve the approximation, which may indicate that the approximation itself is poor.
Finished in 6.1 seconds.
These ideal points are similar to the random walk estimates and show the limited variation possible in a 2-degree polynomial function (essentially a quadratic function). For one session, this model would appear adequate at capturing monthly changes in legislator trajectories.
Finally, we can also examine the individual ideal points by each time point using the summary function:
summary(del_est_spline,pars='ideal_pts') %>% head %>% knitr::kable(.)
Person
Group
Time_Point
Low Posterior Interval
Posterior Median
High Posterior Interval
Parameter Name
NA
NA
NA
0.954922
0.954922
0.954922
L_tp1[1,100]
Plant, Al Sr. 76
D
1995-01-01
-5.494500
-5.494500
-5.494500
L_tp1[1,101]
NA
NA
NA
-6.036150
-6.036150
-6.036150
L_tp1[1,102]
NA
NA
NA
-0.891253
-0.891253
-0.891253
L_tp1[1,103]
NA
NA
NA
-0.163663
-0.163663
-0.163663
L_tp1[1,104]
NA
NA
NA
-0.491950
-0.491950
-0.491950
L_tp1[1,105]
Group-level Time-varying Ideal Points
Finally, we can also change the model’s parameters to look at group-level, i.e. party-level, ideal points. To do so we need to specify the use_groups=T option in the id_estimate function, and we change the restricted parameters to parties:
[1] "Running pathfinder to find starting values"
Finished in 101.0 seconds.
[1] "Estimating model with Pathfinder for inference (approximation of true posterior)."
Pareto k value (20) is greater than 0.7. Importance resampling was not able to improve the approximation, which may indicate that the approximation itself is poor.
Finished in 95.0 seconds.
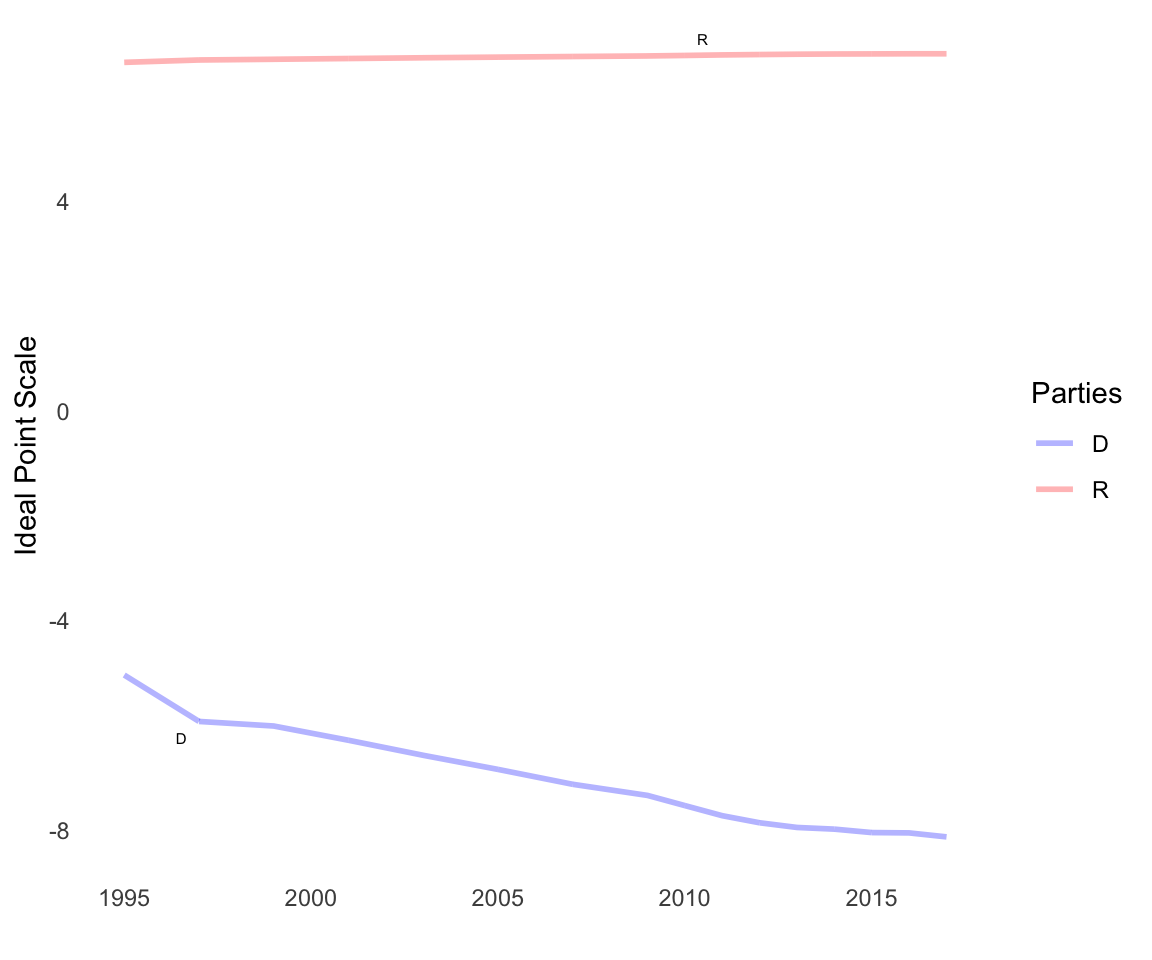
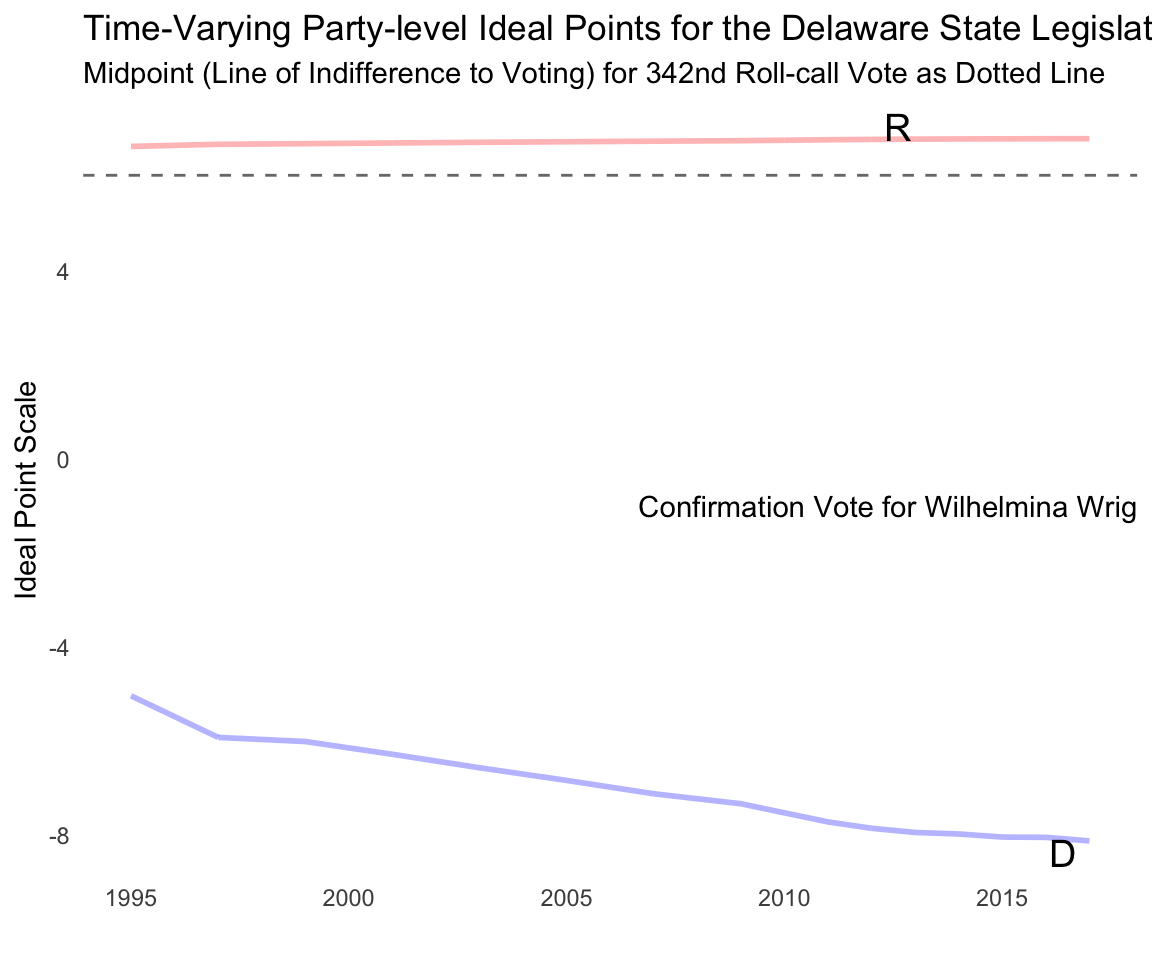
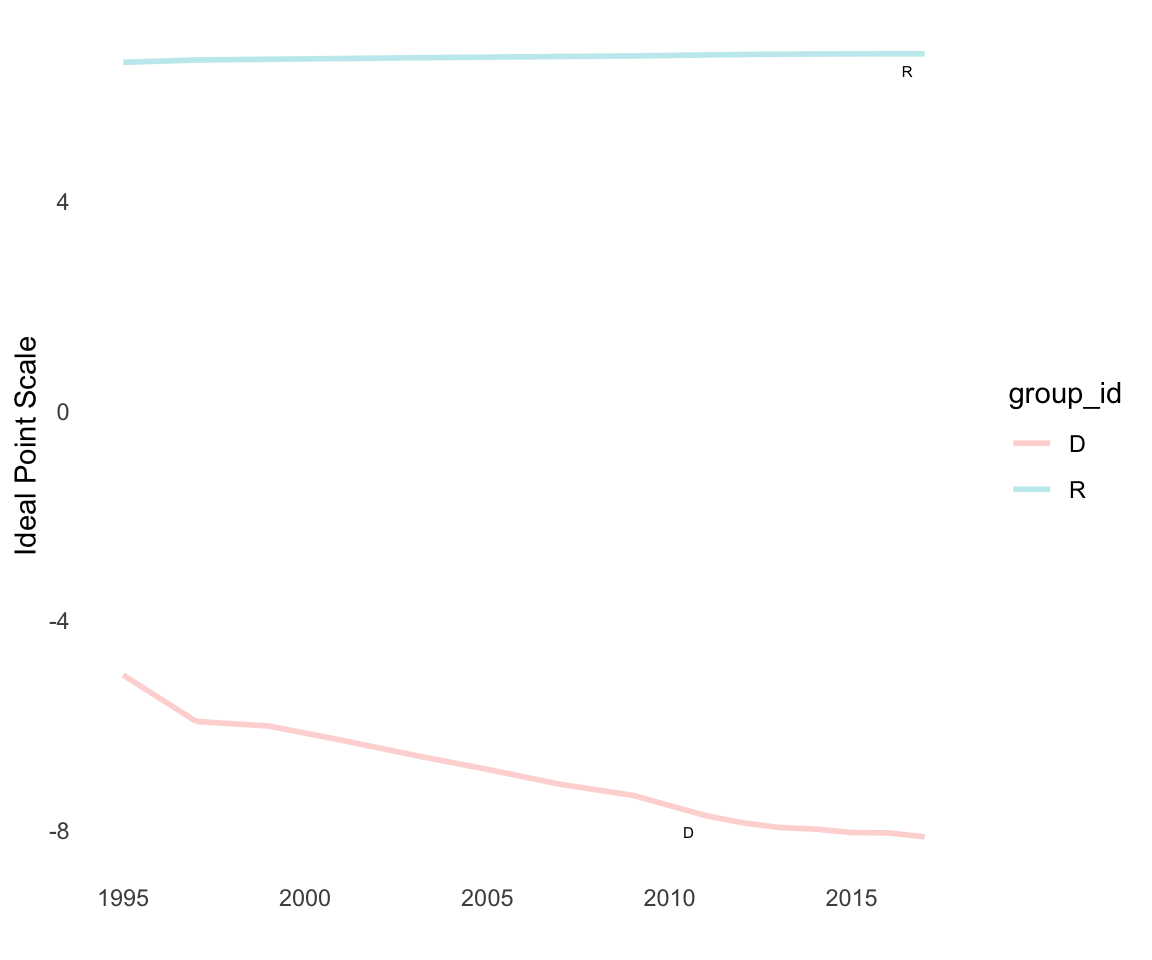
We can also overlay a bill/item midpoint to see where the line of indifference in voting is relative to party positions. In a dynamic ideal point model, the bill/item midpoint will be a straight line as the bill-item midpoint was only voted on in one time point, and hence has only one parameter:
id_plot_legis_dyn(del_est_rw3,item_plot='342',text_size_label =5,include=c('D','R')) +scale_colour_manual(values=c(R='red',D='blue',I='green'),name="Parties") +ggtitle('Time-Varying Party-level Ideal Points for the Delaware State Legislature',subtitle ='Midpoint (Line of Indifference to Voting) for 342nd Roll-call Vote as Dotted Line') +guides(color='none') +annotate(geom='text',x =ymd('2016-01-01'),y=-1,label='Confirmation Vote for Wilhelmina Wright as U.S. District Judge')
As this plot shows, the line of indifference is very close to the Republican party, implying that the vote split the Republican party while Democrats voted as a bloc. Empirically that is very close to the observed votes; all 27 Democrats voted to confirm the judge while 7 out of 6 Republicans did so.
I will now estimate an additional Gaussian process model to use as comparison points to the random-walk model for parties:
[1] "Running pathfinder to find starting values"
Finished in 70.5 seconds.
[1] "Estimating model with Pathfinder for inference (approximation of true posterior)."
Pareto k value (12) is greater than 0.7. Importance resampling was not able to improve the approximation, which may indicate that the approximation itself is poor.
Finished in 68.7 seconds.
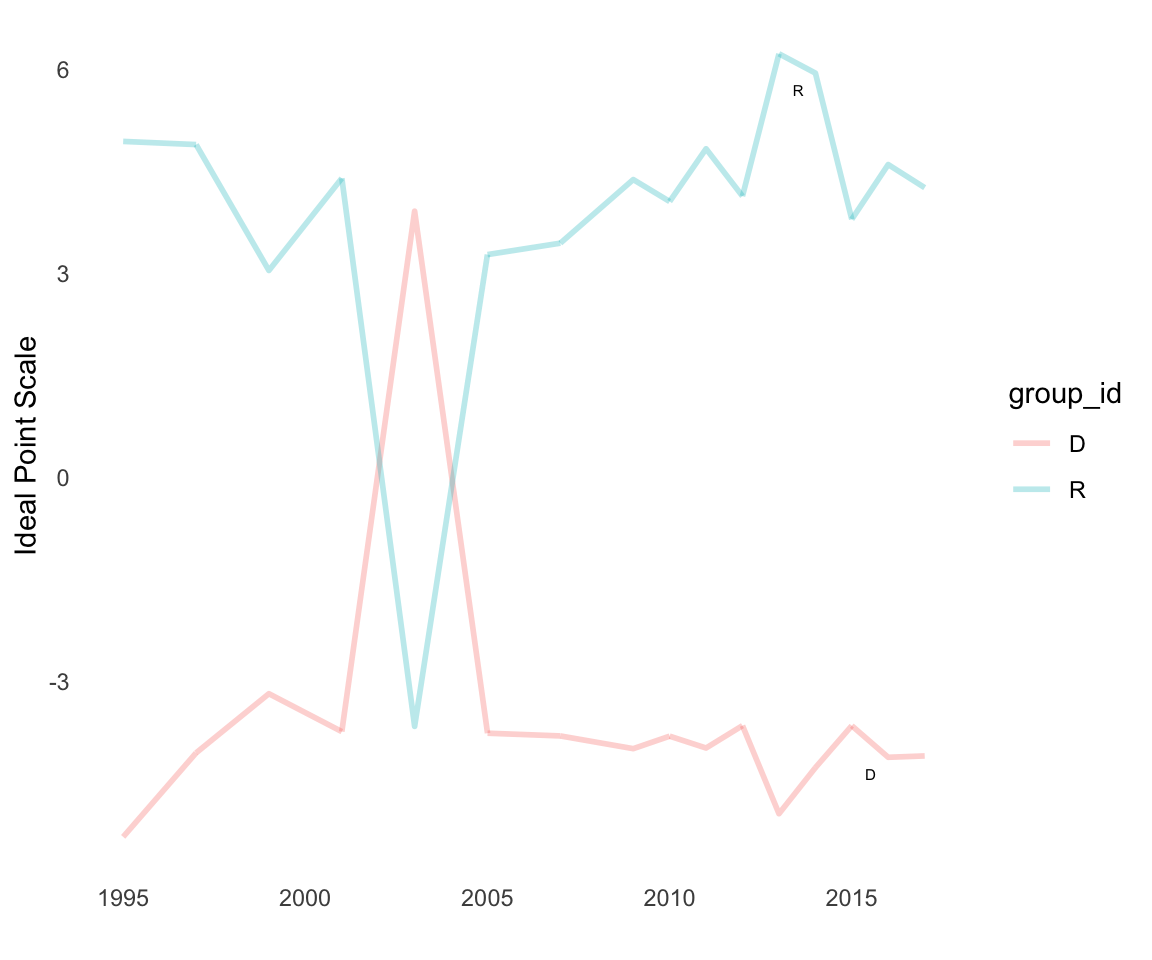
We can then examine the distributions for both models as plots:
id_plot_legis_dyn(del_est_rw3,include=c('D','R'))
id_plot_legis_dyn(del_est_gp1,include=c('D','R'))
This plot shows that are substantial divergences between the different models (each plot is faceted by group_id). The GP model shows a lot more bounce over time relative to the random walk model, which is implausible given the latent trait we are trying to estimate is legislator ideology. In this case, we should prefer simpler models, such as random walks or splines, to estimate a more slowly-changing latent variable. Estimation with HMC rather than the variational approximation could also help.
We could also consider adjusting GP-specific parameters to force a more restrictive fit, though that type of prior adjustment depends on the particular dataset and context. These parameters are given defaults that restrict movement in the ideal points to help ensure identification. As such, they tend to be fairly conservative, but they can be made even more so when necessary. The table below shows these parameters’ values.
Parameters in the Gaussian Process Time-Series Model
Parameter
Description
gp_sd_par
This parameter represents residual variation in the series that the GP does not account for. As such, its default is a very low value, as increasing it will generally increase oscillation in the series.
gp_num_diff
This parameter is a multiplier that is used to set the prior for the length-scale of the GP. Loosely speaking, the length-scale determines the number of times that the time-series can cross zero, and so lowering this parameter will decrease the length-scale and subsequently increase the number of times the series can cross zero. The length-scale is given a prior equal to the difference between the maximum and minimum length of the time series in whatever units it is recorded in (days, weeks, etc) times the parameter gp_num_diff. The second numeric value of this parameter represents the standard deviation of the log-normal prior of the length scale. Increasing the standard deviation will put more weight on the data in determining the amount of flexibility in the time series.
gp_m_sd_par
This parameter has two values that set the GP’s marginal standard deviation. This parameter loosely represents the amount of time-series variation in the series. The first numeric value represents the hard upper limit for this parameter to prevent the series oscillating. The second numeric value is equal to the shape of an inverse-gamma prior defined over the interval between 0 and the first numeric value (the hard upper limit). It is a weakly informative prior that pulls values away from zero to prevent divergences. Increasing the first numeric value (the upper limit) will increase marginal standard deviation, while the second numeric value can increase marginal standard deviation by decreasing its value, resulting in a flatter inverse-gamma prior.